
The Optimistic Iconoclast - Issue #26
The 12.5% Reality - Why Production AI Agents Are Failing


1. Two worlds, same technology
In March, Forrester, in partnership with a16z and the MIT Sloan CIO Panel, surveyed 650 technical leaders. 88% of AI agent pilots never reach production. Average cost per dead pilot: US$ 340K. That same month, Stanford published the AI Index 2026: agents jumped from 12% to 66.3% accuracy on the OSWorld benchmark in twelve months, the same window in which real deployment stayed in single digits. And Anthropic, in its 2026 State of AI Agents Report with over 500 technical leaders, brought the other half: 80% of teams that reached production report positive ROI, with 171% average ROI among survivors (Forrester).
Two worlds. Same technology. Same time window. What the hell is different?
The question that triggered this issue is simple: what separates the 12% that make it from the 88% that die? And how does the most popular hypothesis — “it’s still early, the model will get better” — survive against the data?
It doesn’t. Neither does it, nor the other two popular hypotheses I’m going to test. What survives is more uncomfortable, and more actionable. To get there, I’ll first put the data on the table.
2. Five numbers, no interpretation yet
Before proposing a reading, I’ll lay five findings on the table.
1. Berkeley + IBM (December 2025): 306 agentic AI practitioners across 26 domains. 68% of teams in production limit their agents to no more than 10 steps before requiring human intervention. 47% stop before the fifth step. These teams reached production precisely by operating on a tight scope. It’s the industry’s state of the art.
2. Princeton (February 2026). In the paper Towards a Science of AI Agent Reliability (Rabanser et al.): 18 months of fast capability gains produced small reliability gains. Capability and reliability evolve on independent axes; raising one doesn’t lift the other.
3. Google Research + MIT (December 2025): 180 controlled configurations. Independent agents in chained workflows (long chains) amplify errors by 17.2×. Above 45% single-agent accuracy, adding more agents makes things worse (β̂ = -0.404, p < 0.001). More agents isn’t the answer. In several scenarios, it’s the problem.
4. Cursor IDE (1,200 production environments, December 2025): Agents have 94% accuracy on structured tasks and 12.5% on unstructured tasks. The dividing line is the environment in which the agent operates. Switching to a more sophisticated model doesn’t close that gap.
5. Deloitte (2026), LatAm focus: 21% of Brazilian organizations have at least one agent in production, below the global average. Banking pulls the number up; government and healthcare pull it down. This isn’t slow adoption. The Brazilian operational environment is structurally different, and I’ll come back to that under hypothesis 2.
With the data laid out, three popular hypotheses compete to explain the gap between 12% and 88%. Let’s analyze the three, one by one.
3. Hypothesis 1: “It’s the model. Wait for the next version.”
The reflexive technical reading is the one that comforts the decision-maker most. Agents fail in long chains because the model still isn’t good enough. You “just” need to wait for the next version: Opus 5, GPT-5, Gemini 3.5. That’s how capability and reliability grow. It’s just a matter of patience.
I’ve heard this line in some companies. The confident CTO, three bullet points of OpenAI release notes on the slide. “We’re waiting for the next release; that’s when we unlock everything.” Operations consents, because it’s easier to agree than to demand accountability now. Three months later, same problem, new model name, same line.
The data doesn’t confirm this hypothesis.
The first piece of evidence is elementary math. An agent with 95% success per step looks excellent. 95% is one of the rare AI metrics that genuinely impresses a board. Put that same agent on a 20-step workflow: 0.95²⁰ = 36% overall success rate. Bump per-step accuracy to 98%, spread across 30 steps: 0.98³⁰ = 55%. A perfect-per-step model doesn’t exist, and even if it did, exponential error propagation would crash any long chain. It’s a category of problem distinct from hallucination, one that model sophistication alone doesn’t solve.
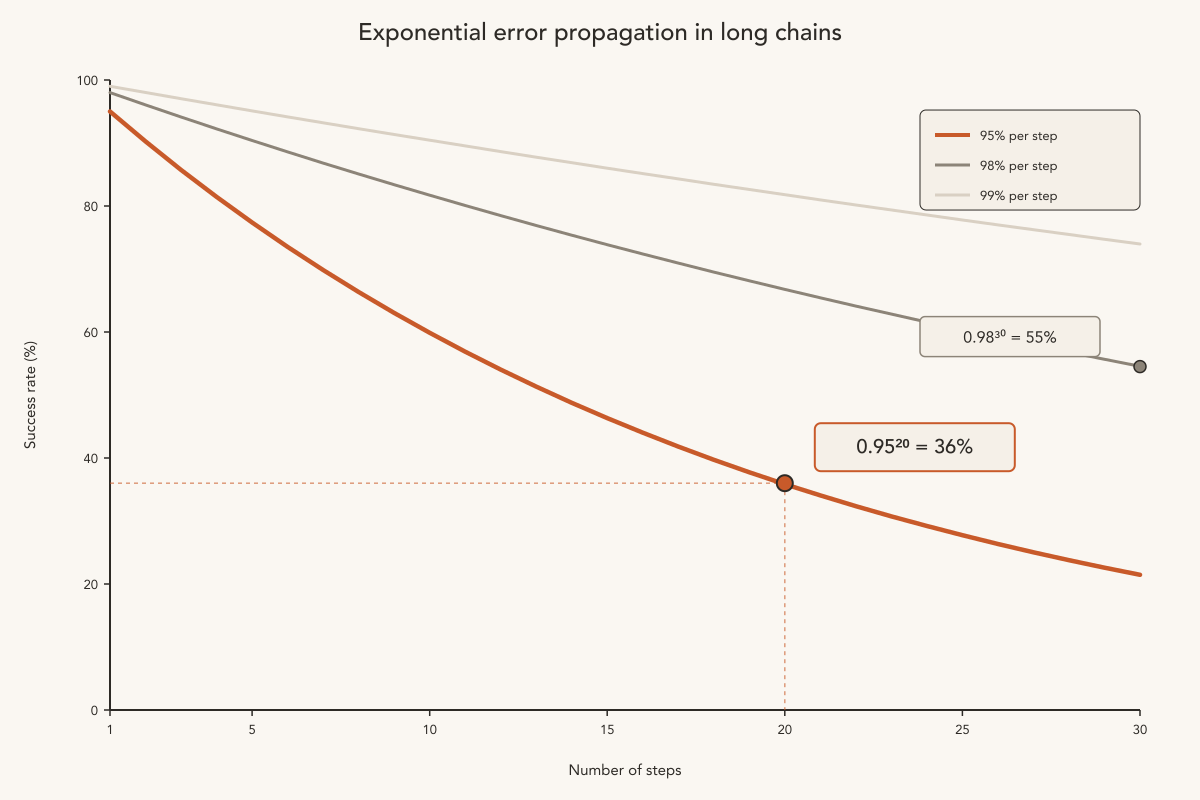
The second piece of evidence closes the door. Princeton (Rabanser et al.) showed empirically that capability and reliability evolved on independent axes over the past 18 months. Capability jumped fast, but reliability didn’t follow. Whoever waits for the next model is waiting for one axis to rise and drag the other along with it. That’s not how it works.
“Reliability requirements differ fundamentally between automation and augmentation use cases.” — Rabanser et al., Princeton, 2026
There’s a layer that escapes even technical reviewers: “evolution” isn’t always upward. On April 23, 2026, Anthropic itself published a post-mortem on a six-week degradation in Sonnet 4.6, Opus 4.6, and Opus 4.7, three of the top models on the market, in real production. Three deliberate decisions (changing the default reasoning effort from high to medium, a caching bug that cleared reasoning history every turn, and a verbosity instruction limiting responses to 25 words between tool calls) tanked perceived intelligence, made the agent forget context, and degraded tool-choice quality. Anthropic’s own internal evaluations failed to reproduce the issues. The signal came from user feedback and online reports. The vendor responsible for top models in production still faces regressions, and deliberate improvements sometimes introduce the very bugs they aim to fix. Waiting for “the next version” assumes linearity. Linearity hasn’t been observed in the past 18 months, and in some periods has been negative.
And there’s one last detail I keep coming back to when someone tells me “it’s still early.” The 12% that reached production operate with the same models available to the 88% that died. Same release window, same APIs, same limitations. If the model were the difference, there would be no difference.
Mustafa Suleyman captures why the hypothesis persists even after refutation:
“One of the issues with LLMs is that they still suffer from the hallucination problem, whereby they often confidently claim wildly wrong information as accurate. This is doubly dangerous given they often are right, to an expert level. As a user, it’s all too easy to be lulled into a false sense of security.” (The Coming Wave, 2023)
It survives in arguments and decision processes because it’s the only hypothesis that doesn’t require redesigning anything. Wait. Install. Repeat the demo.
Verdict: Hypothesis 1 survives as a vector. Models will improve, and improvements matter. But it doesn’t explain the 88% dying right now. The 12% teams reached production with the current models. Waiting for the next is rationalization. The hypothesis dies as root cause.
4. Hypothesis 2: “It’s the benchmark. The measurement changed games.”
The epistemological reading is more sophisticated than the first. The capability numbers (OSWorld 12% to 66.3% in twelve months, SWE-bench virtually human) reflect benchmarks that became easy to game. Agents learned to optimize for the test. The industry is selling demos; production is something else.
Whoever proposes this hypothesis usually shows up with a concrete example: the vendor demo opens a browser, reads a ticket, queries the ERP, creates the invoice, sends it on Slack, closes the case. Six or seven steps. Success. In production, that same agent is configured to stop at step three. The demo lives in a curated environment; real operations don’t.
The hypothesis survives the initial confrontation. But, examined carefully, it’s a symptom of something deeper. Breaking it into three parts:
1. The environment is the dividing line. Going back to one of the numbers from section 2: agents have 94% accuracy on structured tasks and 12.5% on unstructured ones (Cursor IDE, 1,200 production environments). Where the environment is controlled (clean API, structured data, reversible actions), the agent performs. In the real environment, with authentication, a CAPTCHA mid-flow, a custom ERP, a spreadsheet pulling data from four systems, and a contract in a PDF signed in DocuSign, it breaks. Research benchmarks live in the first world; companies live in the second. What we’re measuring leaves out the metric that actually decides deployment.
2. Operational friction, sharper in Latin America. The average Brazilian operation runs on an ERP customized by a local integrator, spreadsheets pulling data from multiple systems, processes approved across three layers of hierarchy, and a contract in a PDF reviewed by legal. That’s the real environment. OSWorld doesn’t have any of that. And Brazil’s AI Legal Framework (Bill 2338/2023), prescribing human-in-the-loop on high-impact automated decisions, just formalizes what operations were already doing out of necessity. The 21% of Brazilian organizations with an agent in production got there despite the environment.
3. Capability isn’t reliability, even with the perfect benchmark. Princeton comes in again, with different framing from section 3. There, they showed capability and reliability evolve on independent axes over time. Here, the paper’s Recommendation 4 brings the operational distinction: reliability requirements differ between automation and augmentation use cases. Practical translation: even a perfect benchmark would measure capability. Sustained operational reliability lives on another axis. You can score 100% on OSWorld and still have an agent that fails in production, because OSWorld is a capability test.
(Worth noting recent work from Berkeley RDI / Kang lab, April 2026, arguing that eight major agent benchmarks can be exploited for near-perfect scores without solving the actual task. It’s a real problem, but secondary to the central question. Even if every benchmark were impossible to game, it would still be measuring the wrong axis.)
As mentioned earlier, Anthropic’s own internal evaluations didn’t catch six weeks of regression in Sonnet 4.6, Opus 4.6, and Opus 4.7. Top models, from the vendor itself, in a product where the vendor had every incentive in the world to detect them. If the best benchmark structure in the industry doesn’t catch regression in its own product, what makes anyone think a generic research benchmark captures sustained operational reliability in a custom ERP in São Paulo?
Verdict: the hypothesis is true as observation. The measurement drifted from the axis, and the vendor has incentive to compete on that benchmark. But it’s a symptom. Why do corporate buyers keep buying based on polished demos in curated environments? Why does operations accept inheriting a decision made on evidence it can’t validate? Hypothesis 2 survives as evidence. And it opens the door to the next, the one that actually survives.
5. Hypothesis 3: It’s the decoupling between decision-maker and operator
The organizational reading is the most revealing. In a traditional software adoption (CRM, ERP, BI platform), the buyer is the operational area. When a sales leadership team buys Salesforce, the sales team operates it. There’s natural coupling between the buying incentive (solve the area’s pain) and the reality of use (daily routine).
With agentic AI, that coupling broke.
The buyer is the CIO, CTO, Chief AI Officer, someone with a more technical bias. The incentive: modernization, showing adoption on the earnings call, delivering the ROI promised at the investment committee. The actual operator is the functional team on the front line. Their incentive: stability, not getting blamed for the agent’s errors, KPIs that still measure human efficiency while the agent runs in parallel. Different utility functions. The vendor sells to the buyer, because that’s who signs. The operator inherits.
The clinical signature is in the data.
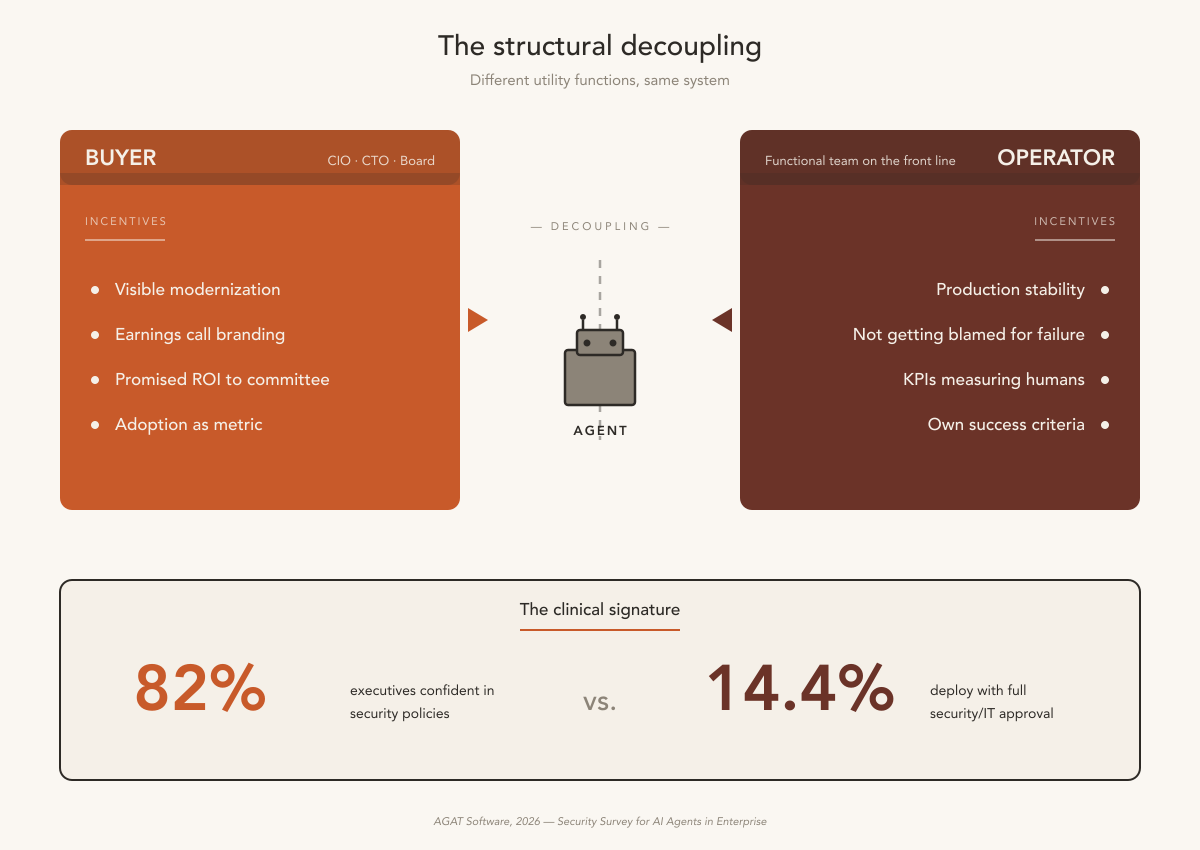
The first piece of evidence is the cleanest. AGAT 2026 surveyed senior executives and security/IT teams, separately. 82% of executives say they’re confident in security policies for agents. Only 14.4% can effectively deploy with full security/IT approval. When five to six times as many executives feel confident as can actually ship to production, the problem is structural. Information doesn’t flow between the level that decides and the level that operates.
The second piece of evidence is the most underestimated. Forrester attributes 41% of failures to “unclear success criteria.” Criteria for whom? If the buyer wanted “launch the agent in 90 days to show at the QBR” and the operator needed “agent that doesn’t cause a production incident,” the criteria were crystal clear from the buyer’s perspective. They were simply the wrong criteria, because operations had different ones.
The third piece of evidence is the most revealing: 85% of successful teams reject third-party frameworks and build custom. Read in technical terms, this looks like a sign of competence (”the good ones build custom”). Read in organizational terms, it’s a symptom. The operator, after inheriting the agent, finds out they need to build custom to survive. The original purchase was useless for real operations. The operator ended up paying twice: once on the license, once on building what should have been specified beforehand.
And there’s a fourth piece, which is the vacuum. Forrester points to ambiguous responsibility, with 26% of failures attributed to what they call “evaluation drift”: the success metric quietly changes over time. Translation: nobody wants to take responsibility for declaring a failure of an agent the board approved. Decoupling produces a vacuum of responsibility. A vacuum of responsibility produces drift. Drift produces eternal pilots.
And the pattern is old.
It has three known waves, in three different industries and decades. In the first, the ERP of the 90s: bought by the CFO/CIO from vendor demos; finance ops, supply chain, and HR inherited the implementation. The canonical case is documented by Thomas Davenport in Mission Critical (2000) and was widely covered by the trade press at the time. Hershey’s lost US$ 150M in 1999 when its ERP, deployed just in time for Halloween, left the operation unable to process orders.
In the second wave, the CRM of the 2000s: bought by the VP of Sales for the dashboard the board wanted to see; the sales force hated the tool because it served the manager. Consistent surveys from Forrester and Gartner over the period showed real adoption rates between 40% and 60% for two decades, across the hundreds of companies studied.
In the third wave, RPA between 2015 and 2020: “digital workforce” sold to COOs by UiPath and Automation Anywhere. Forrester reported scandalously short bot lifespans, with more than 50% of cases needing re-engineering in the first year.
The industry has lived this movie three times. What changes with agentic AI is that the version is sharper. Model versions cycle faster than ERP/CRM/RPA ever did. Autonomy claims raise the buyer’s promise (a colleague instead of a bot, an identity-level leap). Custom builds grow even faster: 85% rejecting third-party frameworks now, against the ~50% RPA saw at the same maturity stage. And publicly gameable benchmarks, something enterprise software never had, complete the picture.
And there’s a team that chose to erase that decoupling from day one.
I’m a co-founder of a small startup that builds agents and uses agents to build them. The other day, a teammate offered to prototype a critical piece on his machine. Hours later, after a design conversation reshaped the problem, another head took over. Nobody voted. Nobody approved. The one who decided was the one who would use it.
When the Berkeley/IBM numbers came out in December, nobody on our team was surprised by the 68% capped at 10 steps. We built without decoupling because we already knew the cost. We’re among the 12% that reach production, and that was a structural choice from day one.
I’ll start naming these two groups from here on. The 12% that reach production: the coupled, those who put decision and operation in the same room before signing. The 88% that die: the orphaned pilots, pilots stuck in the space between buyer and operator, without a real owner.
The hypothesis survives confrontation with the data. And it contains the other two.
“It’s the model” survives as rationalization because, without the operator integrated into the decision, nobody tests the alternatives. The team waits passively for a solution coming from above. Waiting is what people do when they weren’t invited to decide.
“It’s the benchmark” survives because, without the operator integrated into the purchase, the vendor sells to the criterion the buyer knows (a polished demo in a curated environment). The criterion operations would require, sustainable reliability in a real environment, simply doesn’t enter the buying conversation.
Verdict: Hypothesis 3 survives. The three studies that opened this issue start to make sense together: 88% of pilots die because they were bought in one frame of incentives and operated in another; 80% of survivors report ROI because the frame was unified, deliberately, before signing. The 12% won by organizational design of adoption.
6. Synthesis: you don’t hire a new colleague without the team knowing
In March, I wrote about the first agentic workforce, when systems became colleagues (Issue #17). The promise was real and still is. But the industry accepted the promise of the colleague and then used the software acquisition playbook to deliver on it. Launch, license, install, train users, measure adoption. It’s the wrong playbook, because you don’t buy a colleague. You incorporate one.
When you hire a human colleague, even a contractor, even a temp, the team that will work with them gets a say. HR doesn’t decide alone. Operations doesn’t inherit passively. There’s a team interview, onboarding, expectation calibration, a small first project, feedback loops. There’s coupling between who decides and who lives with the decision.
With agents, that coupling was skipped. The CIO signs the contract with the vendor. The functional team finds out about the agent when it shows up in the workflow. The orphaned pilots die in that space between buyer and operator, without a real owner. The coupled, regardless of sector, size, or geography, share one thing: they erased that space. Whoever decided, operates. Or whoever operates, decided.
The board’s operational question, then, stops being “which model to choose.” And becomes another. Three, actually.
7. Three questions that separate coupling from decoupling
Before the board signs the next AI vendor contract, three questions. All three are for the board, not for the technical team, the consultant, or the vendor. If the answers don’t fit on a slide with names, deadlines, and metrics, the agent is headed for the orphaned pilot graveyard.
1. Who is the functional operator of the agent in production, and does that person have a formal voice (with veto power) in the adoption decision before signing?
Ceremonial consultation afterward doesn’t count. If the operator’s name shows up as “to be defined after signing,” decoupling is already baked into the contract. Forrester attributes 41% of failures to “unclear success criteria.” Translation: the operator who would have defined the criteria wasn’t in the room.
2. What is the narrowest scope, defined by a reversible decision, and can the operator reject this scope before signing?
Concrete example: “decide refund/no-refund on transactions below R$ 500, with weekly human audit” (instead of “automate customer service”). Narrow enough for the operator to validate; reversible enough that the board doesn’t need to defend face. And the veto comes before signing, not after (Berkeley/IBM showed 85% of successful teams end up rewriting what they bought). Better to rewrite on paper.
3. What is the reliability threshold (not accuracy, not demo) measured by the operator every day, and what is the rollback criterion declared before deployment?
Princeton: four reliability dimensions: consistency, robustness, predictability, safety. Capability isn’t on the list. The threshold is set by the operator because only they see what fails in production. Measured every day, because silent drift is the most common failure mode. And the rollback criterion declared before, or it falls hostage to the board that approved it.
Three answers, one slide, before signing. Otherwise, one more orphaned pilot on the pile.
8. What the 12% know
Agent capability will keep going up. Reliability won’t follow on its own. And benchmarks will keep being gameable as long as they’re what vendor and buyer agree to measure. None of those three is the central problem.
The central problem is simpler and more strategic. We’re buying agents, new digital colleagues, without the team that’s going to work with them in the decision room. The coupled discovered, deliberately or by luck, that adopting AI is operational incorporation. There’s an owner and deadline defined before signing. There’s a rollback criterion agreed before deployment. There’s a formal voice from the operator before the contract.
In 2026, competitive advantage lives in a place the vendor proposal slide doesn’t capture: in the room where you decide who’s going to live with the agent in production, and whether that person has a voice to say “no, not in this format.”
The coupled know. The orphaned pilots don’t, yet.
📗 Recent publications
The first agentic workforce: how AI systems became colleagues (March 3, 2026)
In March, I wrote that AI systems were crossing the boundary from “tool” to “colleague,” and that this category change required more than technical evolution: it required organizational redesign. The thesis held up, but the operational design for it was missing. This issue delivers it: the three questions that separate coupling (decision-maker is operator) from decoupling (decision-maker delegates to vendor, operator inherits orphaned pilot). #17 named the new colleague. #26 shows how to hire.
🌎 What the world is saying…
Berkeley/IBM (Pan, Arabzadeh et al., December 2025) and Princeton (Rabanser et al., February 2026): Measuring AI Agents in Production (arXiv 2512.04123) and Towards a Science of AI Agent Reliability (arXiv 2602.16666).
This issue rests on two complementary papers.
Berkeley/IBM is the empirical portrait: 306 practitioners across 26 domains, and the finding that tight scope is deliberate design from the industry that reached production.
Princeton is the theoretical skeleton: capability and reliability as independent axes, with Recommendation 4 distinguishing automation use cases from augmentation ones (categorically different reliability requirements).
For anyone reading both, the order matters. Read Berkeley/IBM first, to calibrate operational reality. Then Princeton, to understand why that reality doesn’t change with the next model bump. I read them in reverse order, and lost lots of time trying to understand what I was seeing in production. Right order saves time.
References
UC Berkeley + IBM Research + Stanford + UIUC + Intesa Sanpaolo (Pan, Arabzadeh et al., December 2025) — Measuring AI Agents in Production. arXiv 2512.04123v1. 306 practitioners across 26 domains. Source for the numbers 68% (≤10 steps), 47% (≤5), 74% (human evaluation), 85% (custom build), 70% (use of off-the-shelf models via prompting).
Princeton (Rabanser, Kapoor, Kirgis, Liu, Utpala, Narayanan — February 2026) — Towards a Science of AI Agent Reliability. arXiv 2602.16666v2. Four reliability dimensions (consistency, robustness, predictability, safety); Recommendation 4 on automation vs. augmentation.
Anthropic Engineering (April 23, 2026) — A Postmortem of April 23 Claude Code Quality Issues. Public postmortem on six-week degradation in Sonnet 4.6, Opus 4.6, and Opus 4.7. Available at anthropic.com/engineering/april-23-postmortem.
Stanford HAI (2026) — AI Index Report 2026. Capability benchmarks (OSWorld 12% → 66.3%; SWE-bench virtually human; Terminal-Bench 20% → 77.3%).
Google Research + DeepMind + MIT (Kim, Gu, Park et al., December 2025) — Towards a Science of Scaling Agent Systems. arXiv 2512.08296v2. 180 controlled configurations; 45% single-agent threshold; error amplification 17.2× (independent) vs. 4.4× (centralized).
Anthropic + Material (2026) — 2026 State of AI Agents Report. Survey of more than 500 technical leaders. 80% report ROI; 57% multi-stage; 47% hybrid build/buy.
Forrester / a16z / MIT Sloan CIO Panel (March 2026) — Survey of 650 technical leaders. 88% of pilots don’t reach production; 171% average ROI among survivors; five dominant root causes; US$ 340K average cost on a failing pilot.
AGAT Software (2026) — Security Survey for AI Agents in Enterprise. 82% executive confidence in policies vs. 14.4% who effectively deploy with full security/IT approval.
Berkeley RDI / Kang Lab (April 2026) — Analysis of exploitation of eight major agent benchmarks (SWE-bench, WebArena, OSWorld, GAIA, Terminal-Bench, FieldWorkArena, CAR-bench, among others).
Towards AI / Mohamed Abdelmenem (December 2025) — You’re Paying $20/month for an AI that Succeeds 12.5% of the Time. Cursor IDE with 1,200 production environments. 94% (structured) vs. 12.5% (unstructured).
Mahathidhulipala (December 2025) — Six Weeks After Writing About AI Agents, I’m Watching Them Fail Everywhere (Medium). Source of 0.95²⁰ = 36%.
Deloitte (2026) — State of AI in the Enterprise 2026. LatAm focus: 21% of Brazilian organizations with at least one agent in production, against 31% global.
Davenport, Thomas H. (2000) — Mission Critical: Realizing the Promise of Enterprise Systems. Harvard Business School Press. Documented Hershey’s 1999 case.
Suleyman, Mustafa (2023) — The Coming Wave. Crown.
Russell, Stuart (2019) — Human Compatible: AI and the Problem of Control. Viking.