
The Optimistic Iconoclast - Issue #18
Beyond scale: why the future of intelligence doesn't look like a factory


1. What if scale isn’t the answer?
In January this year, Microsoft lost $381 billion in market cap. In two days. Not because something went wrong — the opposite. Revenue grew 17%. Earnings per share beat analyst estimates. And the market panicked.
The reason fits in a single number: over $100 billion in planned AI infrastructure spending in one fiscal year. Investors looked at the number and did the math no one in Silicon Valley wants to do: how much of this money comes back?
The answer is getting increasingly uncomfortable. The hyperscalers — Amazon, Google, Microsoft — now spend 94% of their operating cash flow on AI CapEx. In 2024, it was 76%. The gap between those two numbers isn’t growth. It looks like a race where the fuel runs out faster than the runway extends.
What if the problem isn’t execution? What if it’s not timing, or talent, or go-to-market strategy? What if the entire model — the idea that intelligence improves linearly with more data, more parameters, more compute — is hitting its economic limit?
That’s the question much of the industry doesn’t seem to want to hear. And this article is about the people already answering it.
2. The machine that eats itself
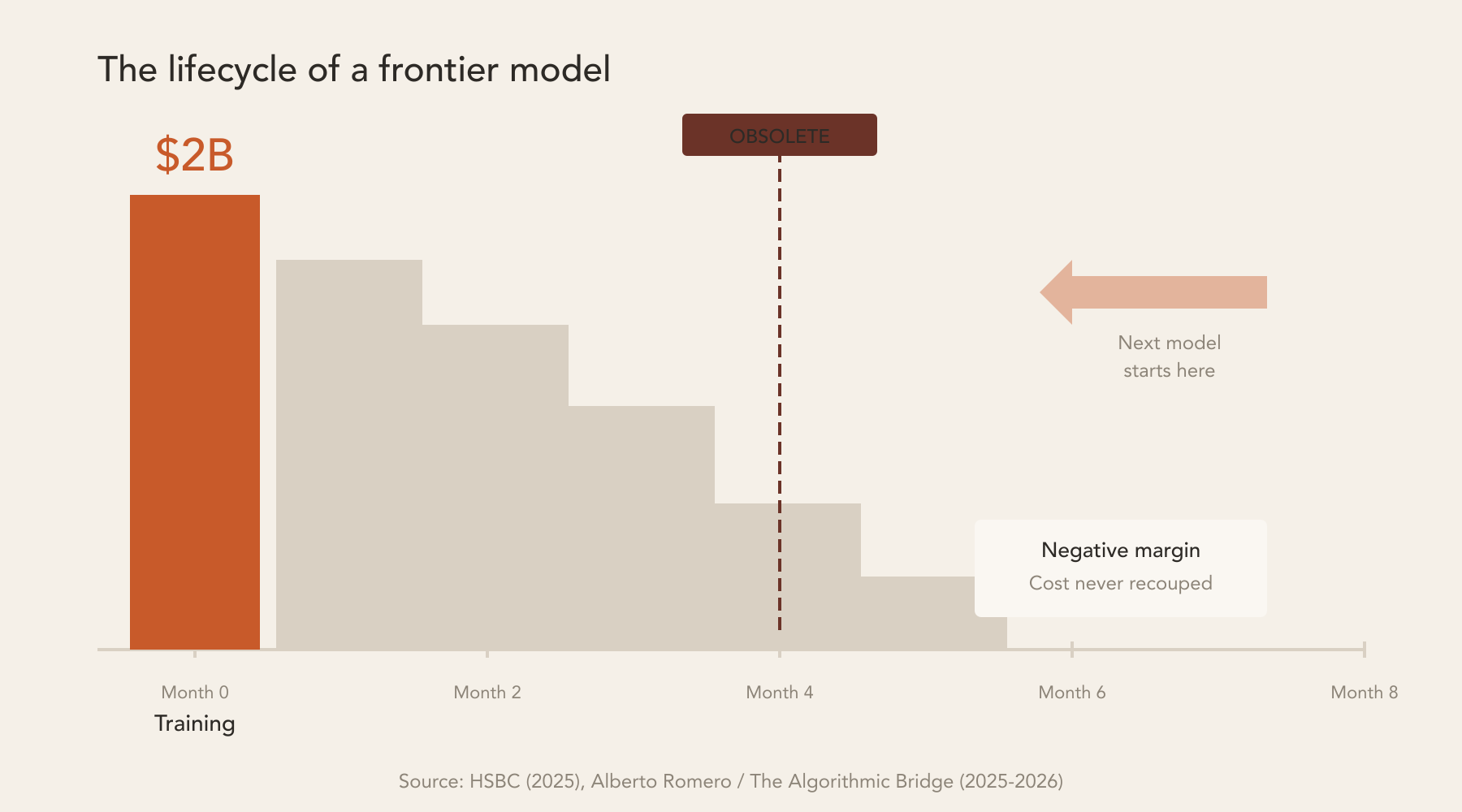
Alberto Romero, of The Algorithmic Bridge, calls Large Language Models “computationally obese.” The metaphor may be catchy, but it undersells the problem. Beyond the fat-shaming analogy, obesity is something you live with over time. What’s happening with frontier models looks more like an arms race where each new weapon becomes obsolete before it pays for its own manufacturing cost.
The numbers: according to HSBC analysts, GPT-5 cost between $1.7 billion and $2.5 billion to train. Four months later, it was already being replaced. OpenAI’s net margin during that period was negative. Romero puts it plainly: “Frontier models are rapidly depreciating infrastructure — OpenAI is retiring models faster than it can recoup costs.”
Think about what that means. The most sophisticated asset the tech industry has ever produced has the shelf life of a pair of running shoes.
To finance this race, big tech has issued nearly $90 billion in bonds since September 2025 — some of them structured off-balance-sheet to keep the debt away from shareholders. Romero has another sharp line: “The adults in the room are running out of allowance.”
Meanwhile, on the ground, AI is already the fastest-growing line item in IT budgets. In some companies, it consumes half of total spending. And most haven’t even reached production yet: according to Deloitte, 45% of leaders expect more than three years to see returns on basic AI investments.
Davos 2026 marked the narrative shift. For the first time, the most “optimistic” forum on the planet swapped “AI scaling” for “AI sustainability.” HBM memory bottlenecks and energy capacity constraints stopped being theoretical concerns for researchers and became operational constraints on CEO agendas. Arm’s CEO was blunt: distributed computing isn’t optional. It’s inevitable.
The irony is that AI already knows how to optimize the infrastructure that hosts it. Meta’s KernelEvolve, documented by Jack Clark in Import AI, uses models to redesign the kernels that run their own systems. It cut cycles from weeks to hours. Performance gains of 4x to 17x.
And here’s the paradox that matters: even when efficiency improves dramatically, total cost doesn’t drop. Cost per token drops. But the number of tokens consumed grows faster than efficiency saves. It’s Jevons’ paradox applied to compute: making something cheaper per unit increases total consumption. The steam engine didn’t replace horses — it created railways. And railways created a demand that horses could never have generated.
That’s why the answer isn’t optimization. It’s architecture.
3. Forests, not factories
The dominant mental model for AI is a factory. Bigger inputs produce bigger outputs. If 100 billion parameters work, a trillion works better. If $10 billion in CapEx generates value, $100 billion generates ten times more. The logic is linear, additive, mechanical.
It works until it doesn’t. And it stopped working.
Economic anthropologist Jason Hickel argues that systems obsessed with scale eventually consume the conditions of their own existence. The AI industry is discovering this in real time.
There’s another model: think of a forest.
A forest doesn’t grow by adding more raw material from outside. It grows through adaptation to context. It recycles nutrients. It distributes resources through underground mycelial networks that no engineer designed. Species diversity isn’t a bug — it’s the architecture that ensures resilience. There’s no “centralized forest” with a single giant trunk consuming all the energy in the ecosystem.
I’ve been arguing since the first issue of this newsletter that organizations need to evolve the same way. Learning loops, not command hierarchies. Continuous adaptation, not five-year plans. It’s what I call organic management: systems that grow like ecosystems, not like assembly lines.
What became clear to me in recent months is that AI architecture itself is going through the same transition. The race for the heaviest monolithic model is hitting diminishing returns — economic, energetic, and perhaps cognitive. The alternative isn’t “less AI.” It’s AI that works like a forest: distributed, recursive, frugal. That learns faster with less. That adapts to context instead of forcing context to adapt to it.
The question that matters isn’t “which model has the most parameters?” but “which system learns fastest with less?”
And three concrete fronts of response already exist.
4. What the forest already knows
If the forest is the mental model, three questions define the post-scaling paradigm. Each one has serious people working on the answer.
How do you make it accessible?
The Frugal AI Hub at Cambridge Judge Business School published a framework that should be on every CTO’s desk. The key number: compression, quantization, and model distillation techniques can reduce total cost of ownership (TCO) by 70% to 90%. Energy consumption drops by up to 80%. Without compromising model utility.
This isn’t theory. It’s survival engineering. Nearly nine out of ten AI startups fail within five years. Most die not from lack of technology, but from lack of economics. Cambridge puts it this way: “Frugal AI is a mindset that transforms scarcity into strength and complexity into clarity.”
For those — and this includes most CTOs trained in the “enterprise scale” school — who think frugality means mediocrity: the alternative is a model that cost $2 billion, lasted four months, and operated at negative margin. Frugality isn’t a limitation. It’s the condition for existence.
How do you make it intelligent without scale?
Romero proposes an architectural alternative he calls Tiny Recursion Models (TRMs). Instead of scaling parameters, these systems learn through iteration and feedback — recursive loops that refine reasoning with modest compute. The inspiration isn’t the factory that produces more by adding more inputs. It’s the organism that gets smarter by repeating, failing, and correcting.
Romero’s thesis is that true intelligence emerges from recursion, not volume. LLMs memorize patterns in monumental datasets. TRMs reason over specific contexts with limited resources. One is the brute force of a steam engine. The other is the adaptation of a nervous system.
How do you measure and govern?
Deloitte proposes the concept of tokenomics: treating the token as the fundamental economic unit of AI, replacing legacy software metrics like licenses and VMs. “A token is not just a technical measure — it is an economic signal.”
In practice, most companies will operate in hybrid mode: SaaS, API, proprietary infrastructure, or some combination of the three. The specific pattern matters less than the discipline of knowing what each token produces.
Deloitte is direct about what separates winners from losers: “AI spend will separate value creators from value eroders.” Those who convert tokens into measurable outcomes create value. Those who accumulate cost without governance destroy it.

Accessibility, intelligence, governance. The three questions of the post-scaling paradigm. None of them are answered with “more parameters.”
5. What grows and what lasts
The AI industry has reached the point where it needs to choose what kind of system it wants to be. One that grows until it can’t anymore. Or one that learns, adapts, and persists.
This isn’t a philosophical choice. It’s economic. It’s energetic. It’s architectural.
Three questions for anyone making AI decisions today:
First: when was the last time you measured cost per outcome, not cost per token? If the answer is “never,” you’re managing consumption, not value.
Second: does your AI architecture depend on an ever-larger monolithic model, or on multiple smaller systems that coordinate? If the answer is the former, you’re building a factory in a market that rewards forests.
Third: what happens to your operation when the model you use today becomes obsolete in four months? If the answer is “we buy the next one,” you don’t have an AI strategy. You have a subscription with an expiration date.
If you want to know where to start: the Cambridge Frugal AI framework is public, free, and applicable tomorrow. Compression, distillation, quantization. Three techniques that reduce the cost of your AI operation without reducing utility. It’s not the only path, but it’s the first step that doesn’t require convincing anyone of a philosophical thesis. It requires a spreadsheet and a decision.
The next wave of AI innovation won’t reward those who spend the most, but those who build systems that adapt — that distribute instead of centralize, that treat scarcity as a design discipline, not as an obstacle to be overcome with more money.
Factories produce. Forests persist. Which model are you betting on?
📚 Recent publications
Normal AI: the pragmatic counter-narrative (01/06/2026)
In issue #9, I argued that the dominant AI narrative oscillates between two equally useless extremes: messianic hype and existential panic. Arvind Narayanan and Sayash Kapoor propose a third way — Normal AI: artificial intelligence as pragmatic infrastructure, not as a mystical force.
What I didn’t know yet was that the technical alternative was already taking shape. Not in the labs competing for more parameters, but in the ones competing for fewer. Today’s issue connects the cultural diagnosis from that edition with the architectural prescription: frugality, recursion, distribution. Normal AI was the question. This issue is one possible answer.
🌎 What the world is saying...
Alberto Romero — “Silicon Valley Is Obsessed With the Wrong AI” (The Algorithmic Bridge, 10/20/2025)
Romero argues that Silicon Valley’s fixation on Large Language Models is myopic. The real frontier lies in alternative architectures that mimic recursive reasoning rather than scaling parameters. He calls LLMs “computationally obese” and compares the AI race to the railway mania of the nineteenth century: valuable at its core, inflated beyond reason.
The thesis: true intelligence emerges from recursive learning loops, not parameter counts. Tiny Recursion Models can achieve deeper reasoning with modest compute, opening the path to personalized, adaptive, and energy-efficient AI.
The question he asks — “are we scaling the right thing?” — is the same question the market asked Microsoft in January. The difference is that Romero already has an answer.
References
Bloomberg/CNBC (2026) — Microsoft Loses $381B in Worst Week Since March 2020. Market reaction to $100B+ in AI infrastructure spending.
HSBC (2025) — GPT-5 training cost estimate: $1.7–2.5 billion.
Alberto Romero / The Algorithmic Bridge (2025–2026) — Silicon Valley Is Obsessed With the Wrong AI; Why Silicon Valley Can’t Afford Its Own AI Ambitions; Frontier AI Models as Rapidly Depreciating Infrastructure. Critique of LLM gigantism, CapEx exceeding cash flow, 4-month depreciation cycle.
Cambridge Judge Business School / Frugal AI Hub (2025) — Accelerating a Frugal AI Ecosystem. Framework for 70–90% TCO reduction and up to 80% energy savings. AI startup failure rate: 85–95% within five years.
Deloitte (2025) — The Pivot to Tokenomics. Token as fundamental economic unit. 45% of leaders expect 3+ years for ROI. Generate/Consume/Run framework.
Jack Clark / Import AI #439 (2026) — AI Infrastructure Self-Optimization at Hyperscale. Meta KernelEvolve: 4–17x gains in inference kernel performance.
Arm Newsroom / Davos 2026 (2026) — Narrative shift from “AI scaling” to “AI sustainability.” Memory and energy bottlenecks as operational constraints.