
The Optimistic Iconoclast - Edition #29
The harness matters more than the model, and there’s a debate underway


“Harness” has become the buzzword in AI. Before the next proposal crosses your desk, it’s worth understanding what’s at stake: where the term came from, what the real anatomy of a harness is, and why two serious sides are saying opposite things about the same statistic.
1. The week the word showed up three times
In April 2026, Anthropic launched Managed Agents in public beta. Seven days later, OpenAI published an Agents SDK update with the same promise, similar vocabulary, different pricing. In May, a CTO at a Brazilian company (around 80 engineers distributed across product, infrastructure, and platform teams) received three vendor proposals using the word “harness” in the email body. Two in Portuguese, one in English. None of the three defined what they meant by it.
The first came from a platform vendor. For them, “harness” was the orchestration layer they’d been selling for two years, with a new name on the cover. The second came from a mid-sized consulting firm. For them, “harness” was a governance framework still under construction: the slide had boxes, but the contents of the boxes were still being built. The third came from an observability company. For them, “harness” was exactly the product they’d been selling all along, now with a label that finally communicated why it mattered.
Three uses. Three meanings. A single term becoming standard before its definition stabilizes.
This CTO’s situation is repeating itself at technical decision tables this year. Anyone who’s been operating technology long enough recognizes the pattern. It happened with “cloud” between 2008 and 2012. It happened with “DevOps” between 2010 and 2014. It happened with “microservices” between 2014 and 2017. Each of these terms went through a six-to-eighteen-month window in which it meant everything and nothing before gaining operational shape.
Now it’s “harness” going through this. And this edition is an attempt to give it shape before the term becomes a premise.
2. Where the word came from
The word “harness” wasn’t born with AI. It comes from classical software engineering, with three traceable moments leading up to the proposals the CTO in the previous section received this month: the origin (1979), the conceptual bridge (2023), and the wave of commercial adoption (2025-2026).
The origin. In 1979, Glenford J. Myers published The Art of Software Testing, one of the first systematic books on software testing, and coined the term test harness: a setup of drivers (which invoke the code) and stubs (which simulate missing dependencies) whose function is to create a controlled environment where code can be executed in isolation. The harness wasn’t the code being tested. It was what surrounded the code to make the test possible.
The conceptual bridge. In 2023, Beren Millidge, a researcher and entrepreneur working in artificial intelligence and computational neuroscience, proposed in an essay an analogy that would circulate quickly among LLM systems engineers: a raw language model is a processor with no RAM, no disk, no I/O. “The context window serves as RAM (fast but limited). External databases function as disk (large but slow). Tool integrations act as device drivers. The harness is the operating system.” The testing term from the 1970s now had a computational metaphor that fit LLM system architecture. The conceptual bridge was complete, even if it hadn’t yet entered commercial vocabulary.
The adoption wave. In November 2025, Anthropic published Effective harnesses for long-running agents and described its Claude Agent SDK as a “powerful, general-purpose agent harness.” The term was in internal use, not yet a headline. In December and January, Phil Schmid and Aakash Gupta published analyses arguing that “2026 is the year of agent harnesses.” In February 2026, Mitchell Hashimoto (co-founder of HashiCorp and creator of Terraform) published Engineer the Harness, popularizing a specific method: “every time you discover that an agent has made a mistake, you take the time to engineer a solution that prevents that mistake from happening again.” Within days, OpenAI and Anthropic published dedicated posts (OpenAI: Harness engineering: leveraging Codex in an agent-first world; Anthropic: Harness Design for Long-Running Application Development). In April, both companies launched commercial products with the word in the name: Anthropic Managed Agents (April 8) and OpenAI Agents SDK update (April 15). The term moved from internal lab jargon to shared vocabulary across the three major labs, becoming an established commercial category.
Worth pausing here to address the most common objection: why accept another term when “orchestration” was already in the vocabulary? The answer is in the semantics. “Orchestration” communicates logical coordination: who calls whom, in what order, with what retry logic. It doesn’t communicate physical restriction, supervision, accountability. “Harness” carries that image because that’s exactly what the term means at its origin: the apparatus that decides what the draft horse can do, not what coordinates its movements.
The choice of term, in other words, is technical. The whole sector needed a word that communicated constraint, not flow. It accepted “harness” not because it’s prettier than “orchestration,” but because it finally names the part of the problem that was invisible while the vocabulary was about coordination.
3. Anatomy in six dimensions
Before the debate about what matters more, model or harness, it’s worth having the anatomy clear. An operational harness carries six dimensions. They show up in any serious implementation, under different names in each context: harness, agent factory, control tower, agentic platform.
Scope. What the agent can touch and what’s out of scope by design. Which databases it queries. Which actions it can execute. Which it can execute with human approval. Which it simply cannot attempt.
Guardrails. Restrictions enforced at execution time. Sandboxing, kill switches, per-session budget limits, allow-lists of permitted domains. The difference between scope and guardrail: scope is an architecture decision; the guardrail is what enforces that decision at runtime.
Memory. How context persists. What returns between sessions, what disappears, what stays attached to a decision for later reconstruction. Includes decision lineage: not just what the agent decided, but with what information in front of it.
Tools. The APIs and integrations the agent can call. CRMs, ticketing systems, internal services, specialized models. Includes the tool schema: how the agent knows what each one does.
Orchestration. The sequence of calls, the workflow, retry logic, error handling. This is the only dimension the prior vocabulary already called “orchestration.” It’s part of the harness, not the whole harness.
Supervision and observability. What stays on record. Audit logs, execution metrics, dashboards for the human who needs to understand what happened. Includes human-in-the-loop at specific points in the execution.
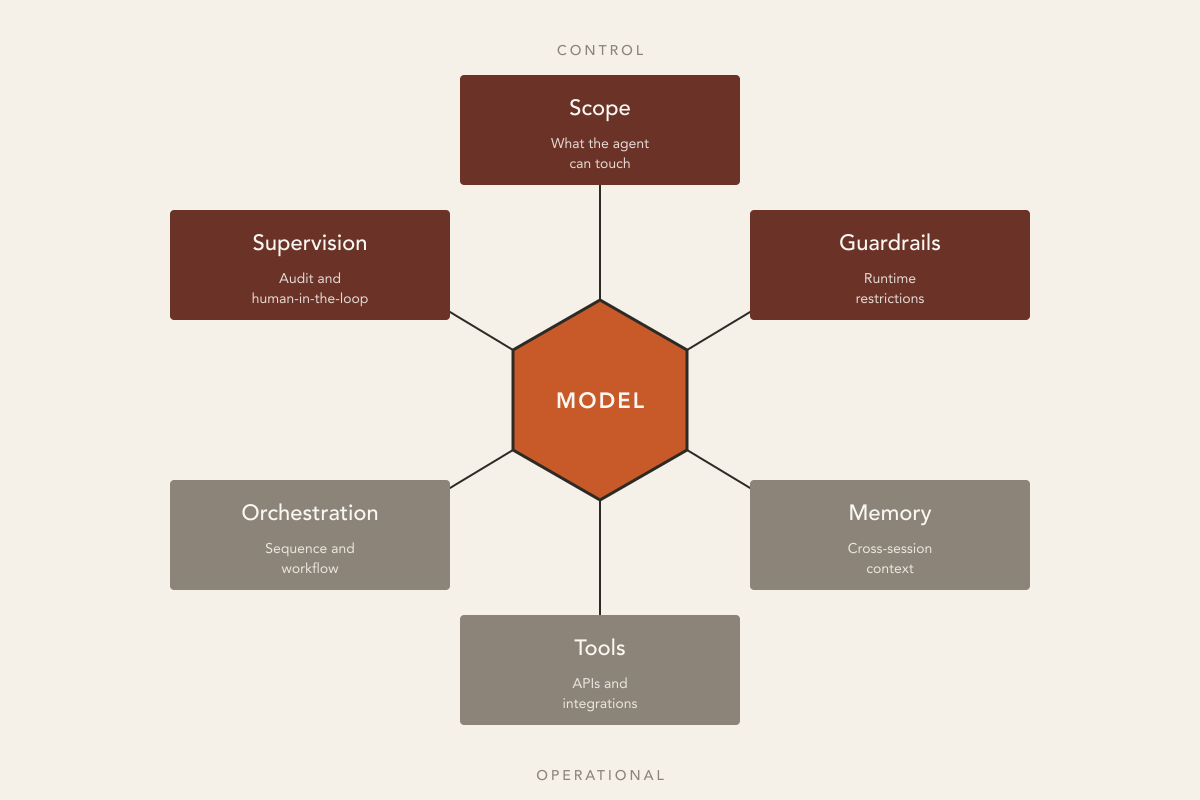
The first useful reading from this list: orchestration is one of the six dimensions. The harness is the whole. The confusion between the two terms is literal: orchestration has been around longer, gained its own tools (Airflow, Temporal, Step Functions), and the sector got used to calling anything that coordinated execution “orchestration.” When agents appeared, it became clear that coordinating wasn’t enough: you needed to restrict, supervise, and give accountability. The other five dimensions needed names of their own.
Vivek Trivedy, of LangChain, coined the formula that has been circulating among engineers since February: “if you’re not the model, you’re the harness.” Everything that isn’t the LLM’s probabilistic brain falls into the six dimensions above. The agent in production is the composition of the two.
The number that made this debate impossible to ignore appeared in March 2026. Anthropic accidentally published a 59.8 MB source map alongside an npm release of Claude Code (version 2.1.88), exposing the product’s complete TypeScript codebase. VILA-Lab analyzed the 1,884 files and ~512,000 lines that came in the package. They classified each file by function: AI decision logic, or harness (permission pipeline, context management, sandboxing, tool router, recovery infrastructure). The result: 1.6% is AI decision logic. 98.4% is harness.

Roughly sixty to one. In code proportion, the apparatus around the model is about sixty times larger than the apparatus that makes the decisions. That number defines the terrain of the next section’s debate.
4. The numbers that carry weight
Three pieces of empirical evidence have converged over the last six months to support the side of the debate that places the harness as the decisive axis. Each comes from a different source, with a different method. Presented in increasing order of strength.
LangChain - Terminal Bench 2.0. In February 2026, in the post Improving Deep Agents with Harness Engineering, Vivek Trivedy published the results of a controlled experiment. The team changed only the harness (system prompts, tools, middleware) and kept the model. Terminal Bench 2.0 performance went from 52.8% to 66.5%: a 13.7 percentage point gain, without swapping the model. An editorial note: LangChain sells a harness framework, so the result carries source bias. Even discounting the bias, the experiment was controlled: a single variable, a public method.
Berkeley/IBM - Measuring Agents in Production. In December 2025, a consortium of 25 researchers (Berkeley, Stanford, UIUC, IBM, and Intesa Sanpaolo) published the paper Measuring Agents in Production (MAP). Lead authors: Melissa Z. Pan, Negar Arabzadeh, Paul Castro, Marquita Ellis. Methodology: 306 practitioners surveyed + 20 case studies across 26 different domains. Two numbers from the paper are particularly useful for the present discussion. First: 68% of agent systems in production execute at most 10 steps before human intervention. Second: 70% rely on prompting as the main control mechanic. The reading: real agent operation in production, in 2025-2026, runs inside tight harnesses. What works is what stays in narrow scope, with a human close by. The rest doesn’t reach production. Edition #26 began with this observation. The MAP paper is the systematic evidence that was missing.
McKinsey - Agent Factory. In April 2026, McKinsey published The AI Revolution in Software Development, with a four-level taxonomy of productivity in software development:

The jump from L3 to L4 is 10x. McKinsey studied the top quintile of ~300 listed companies and the central conclusion is simple: giving developers AI tools (L2) doesn’t move the needle. Companies that actually grow re-architect the whole operation (L3 and L4). For this newsletter’s reader, the most relevant Latin American anchor is LATAM Airlines: the company is reporting +50% productivity with smaller teams operating in the agent factory model.
The math that closes the argument. There’s a simple calculation that helps explain why the harness matters so much. Consider an 8-stage agentic workflow. If each stage has a 95% success rate, the whole workflow has 66.3% end-to-end success (0.95⁸). To reach 92.3% end-to-end, each stage needs 99%. The gap between 95% and 99% per stage isn’t in the model, which generally fluctuates within a narrow band across vendors. It’s in the harness: scope that doesn’t overflow, guardrails that catch errors before they propagate, memory that doesn’t lose context in transition, observability that points to the stage that failed. The model sets the ceiling. The harness defines how much of that ceiling reaches production.
5. The asymmetry of the debate
Before inventorying the two sides, it’s worth naming the asymmetry between them. The side that argues “the harness is the moat” has the empirical anchors: VILA-Lab’s 1.6% vs 98.4% number, LangChain’s 13.7 percentage points, Bain’s control tower framework. The side that argues “the model is the moat” has the engineers who built the product: the creator of Claude Code, OpenAI’s chief reasoning researcher, the scientist who just migrated from Tesla and OpenAI to Anthropic’s pre-training team. The two sides converge on the evidence. They diverge on the interpretation. That asymmetry, empirical argument against the builders’ argument, is the first honest observation possible about the debate.
The “harness is the moat” side. The numbers speak. VILA-Lab showed that 98.4% of Claude Code’s code is harness, not AI decision logic. LangChain documented 13.7 percentage points of improvement by changing only the harness. Bain, in AI Enterprise: Code Red (January 2026), prescribed agent factory + control tower as a mandatory scaling pattern. In April 2026, Google Cloud Next presented the “Agentic Enterprise Control Plane” as the new platform layer. In May, at ServiceNow Knowledge 2026, the AI Control Tower with NVIDIA OpenShell and Project Arc was announced. Anthropic, in March, renamed its Claude Code SDK to Claude Agent SDK: the term moved from a specific product to the category. Five companies, three continents, same direction in six months. Wherever corporate investment is flowing, it’s flowing into the harness.
The “model is the moat” side. Here the argument is more internal than commercial. Boris Cherny, creator of Claude Code, in an interview on the Latent Space podcast: “the harness is the thinnest possible wrapper over the model. We literally could not build anything more minimal. All the secret sauce: it’s all in the model.” Noam Brown, OpenAI’s chief reasoning researcher, has publicly argued that as reasoning models advance, the scaffolding around them will be replaced by direct model capability. Andrej Karpathy, on May 19, 2026, announced he was joining Anthropic’s pre-training team. He went to the team that builds the model, not to Claude Code’s infrastructure. Each of these signals is suggestive evidence, not proof. But three engineers of that caliber taking the same position, in three months, isn’t noise.
And Anthropic’s internal philosophy aligns. The description circulating among internal engineers is that Claude Code’s harness is a “dumb loop,” a simple structure based on a while loop, with no search trees, no elaborate reflection. The intelligence lives in the model, not in the loop’s complexity. For the “model is the moat” side, the harness isn’t the product. It’s the interface between the product and the user.
The Cherny tension. The same VILA-Lab statistic (1.6% decision logic, 98.4% harness) gets cited by both sides, with opposite readings. For the “harness is the moat” side, the number proves where the IP is: 98.4% is integration, complexity, competitive defensibility. For Cherny, “we literally could not build anything more minimal”: the 98.4% is necessary plumbing, and the entire intelligence lives in the 1.6%. The same measurement. Two theses. Both internally coherent. An honest piece doesn’t resolve the tension. It observes that it exists.
The debate should resolve over the next 12 to 18 months. If Brown and Karpathy are right, reasoning models will progressively absorb what’s currently the harness’s responsibility, and the relevance of the six dimensions outlined in Section 3 will diminish. If VILA-Lab, Bain, and Google are right, harness is the operational name for what separates mature AI products from demos. But the CTO’s architectural decision is today. Regardless of who wins, understanding the anatomy of the harness changes how you read proposals and roadmaps.
6. Implications across three planes
Technical. The CTO who internalizes the anatomy of the six dimensions reads vendor proposals differently. When a proposal mentions “agent automation” or “AI workflow” without detailing Scope (what the agent can touch), Guardrails (what stops it from touching what it shouldn’t), Memory (how context persists between sessions), and Supervision (how the human sees what happened), the proposal sold a model and disguised the absence of a harness. The yardstick isn’t checking whether the six words are in the presentation. It’s verifying whether the six dimensions are architected, or whether they’re implicit (and therefore absent).
Governance. Accountability lives in three of the harness’s six dimensions: Guardrails, Tools, and Supervision. When an agent makes a consequential decision, the audit question isn’t “which model did it use?” It’s “what permissions did it have? Which tools were available? What record was left?” Anthropic’s philosophy (dumb loop with intelligence in the model) and Bain’s framework (agent factory + control tower) are different stances on risk posture. But both operate inside the harness. What decides governance is the architecture of the harness, not the model.
Paradigm shift. The question has moved from “which model do I choose?” to “which harness do I build or buy?”
The transformation layer is on the same scale as three previous turns. ERP to SaaS. Monolith to microservices. On-prem to cloud. Each one redefined what counted as responsible architecture for an entire decade.
CTOs who lived through those transitions recognize the pattern: the new category starts as buzzword, becomes operational distinction, then becomes a reading yardstick for proposals, then becomes premise. We’re at step two.
7. The name of what matters
The term “harness” names a reconceptualization of the problem. The apparatus around the model is what separates an AI demo from a product in production. The model’s intelligence sets the ceiling. The apparatus defines how much of that ceiling reaches the world.
The CTO we saw receiving three proposals in May now has a yardstick for reading the next one. She’ll judge by the six dimensions architected underneath, not by the model on the cover.
The category solidifies when the reading yardstick changes. The vocabulary takes. The investment follows.
By the time the debate is settled, the operational question will have moved from “is a harness really necessary?” to “which harness?” And that conversation will feel as obvious as which cloud, which microservices stack, which ERP SaaS.
The turn has already started. Those who understand the difference stop buying models and start buying harnesses, even if they still call them by another name.
📗 Recent issues
The Rise of AI-Native Architecture (Edition #16, Feb 24, 2026)
Three months ago, in edition 16, I described the architectural progression from monolithic LLMs to coordinated multi-agent systems, what I called “AI-native architecture.” That edition named the destination. This edition names the apparatus that decides whether the destination reaches production.
Multi-agent architectures only work when each agent has its own harness: scope, guardrails, tools, memory, orchestration, supervision. Without a harness, multi-agent is a PowerPoint diagram. With a harness, it’s operation.
🌎 What the world’s been saying…
Improving Deep Agents with Harness Engineering - Vivek Trivedy, LangChain (Feb 17, 2026)
This is the post that anchored “harness engineering” as a discipline. The central figure (13.7 percentage points of improvement on Terminal Bench 2.0 just by changing the apparatus) already appeared in section 4. But the post has a contribution that deserves separate attention: it names the three operational levers of harness engineering: system prompts, tools, and middleware (hooks around model and tool calls).
These levers are the first practical translation of section 3’s six dimensions into the vocabulary of the engineer who will actually build. Worth noting the conflict of interest: LangChain sells a harness framework. The bias is on the table. Even discounted, the post is a milestone for the discipline.
References
Glenford J. Myers (1979) — The Art of Software Testing. Wiley. Etymological origin of “test harness.”
Beren Millidge (2023) — Essay with LLM-as-CPU analogy; harness as operating system.
Anthropic Engineering (Nov 2025) — Effective harnesses for long-running agents. Coined “general-purpose agent harness” for the Claude Agent SDK.
Phil Schmid; Aakash Gupta (Dec 2025 - Jan 2026) — Public arguments: “2026 is the year of agent harnesses.”
Pan, Melissa Z.; Negar Arabzadeh; Paul Castro; Marquita Ellis et al. (December 2, 2025) — Measuring Agents in Production (MAP). arXiv:2512.04123. Consortium of Berkeley + Stanford + UIUC + IBM + Intesa Sanpaolo. 306 practitioners surveyed + 20 case studies across 26 domains. 68% of production systems execute ≤10 steps before human intervention; 70% rely on prompting.
Bain & Company (Jan 2026) — The AI Enterprise: Code Red. Agent factory + control tower.
Vivek Trivedy / LangChain (February 17, 2026) — Improving Deep Agents with Harness Engineering. Primary external reference. 13.7pp improvement on Terminal Bench 2.0 (52.8% → 66.5%). Conflict of interest declared: LangChain sells a harness framework.
Mitchell Hashimoto (Feb 2026) — Engineer the Harness. Popularization of the continuous-correction method.
OpenAI Engineering (Feb 2026) — Harness engineering: leveraging Codex in an agent-first world.
Anthropic Engineering (Feb 2026) — Harness Design for Long-Running Application Development.
Anthropic (Mar 2026) — Rename: Claude Code SDK → Claude Agent SDK.
VILA-Lab (Mar 2026) — Analysis of the leaked source map from Claude Code v2.1.88 (1,884 files / ~512,000 lines). 1.6% AI decision logic vs 98.4% harness.
Boris Cherny (2026) — Interview on the Latent Space podcast.
Noam Brown / OpenAI (2026) — Public statements on reasoning models absorbing scaffolding.
Bain & Company (2026) — Google Cloud Next 2026: The Agentic Enterprise Control Plane Comes into View.
McKinsey & Company (Apr 2026) — Reimagining Tech Infrastructure for and with Agentic AI (Tournesac, Gundurao, Lau, Sachdeva). Mesh architecture + 4 foundational capabilities.
McKinsey & Company / Rewired (Relyea, Harrysson, Wiley, Apr 2026) — The AI Revolution in Software Development. Four-level productivity taxonomy (1x → 20x). LATAM Airlines +50% productivity with smaller teams.
Anthropic Managed Agents (April 8, 2026) — Public beta launch.
OpenAI Agents SDK update (April 15, 2026) — Launch.
Andrej Karpathy (May 19, 2026) — Public announcement of move to Anthropic’s pre-training team.
ServiceNow Knowledge 2026 (May 2026) — AI Control Tower + Project Arc + partnership with NVIDIA OpenShell.